


Building a Scalable Environmental Data Pipeline with Apache Airflow, Spark, JupyterLab, PostgreSQL, and Docker

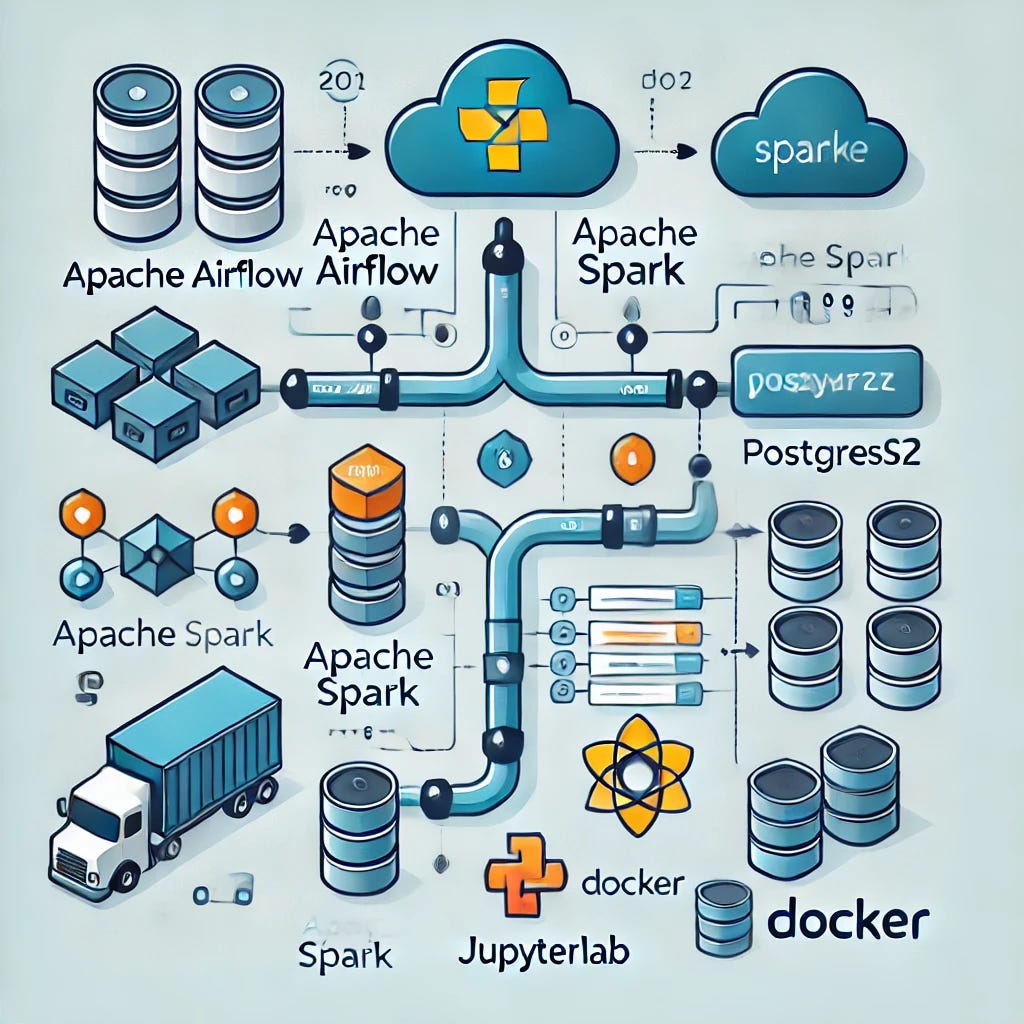
In an age where data drives decision-making, understanding environmental data has never been more critical. From tracking air quality to predicting extreme weather events, leveraging data effectively can provide valuable insights. But managing and processing such vast amounts of data requires a sophisticated infrastructure. Enter the Environmental Data Pipeline—a scalable and modular solution that integrates Apache Airflow, Apache Spark, JupyterLab, PostgreSQL (as a data warehouse), and Docker to efficiently collect, process, and analyze environmental data.
Why Create an Environmental Data Pipeline?
Environmental data management poses several challenges:
Diversity and Volume: Data comes from various sources like weather APIs, air quality sensors, and satellites.
Real-Time Processing: Continuous data streams require real-time or near-real-time processing.
Scalability: The solution must handle increasing data loads while remaining cost-effective.
The Environmental Data Pipeline addresses these challenges by integrating modern, open-source technologies to create a robust, flexible, and scalable framework.
Core Technologies and Architecture
The pipeline leverages a stack of powerful open-source technologies:
Apache Airflow: Orchestrates data workflows, schedules data collection, and manages dependencies between different tasks.
Apache Spark: Provides a distributed computing framework for large-scale data processing.
JupyterLab: Offers an interactive development environment for data exploration and analysis.
PostgreSQL: Acts as a data warehouse to store structured environmental data, enabling efficient querying and data management.
Docker: Containerizes all services, ensuring consistency across environments and simplifying deployment.
ClickHouse (Optional): A high-performance analytical database for fast, efficient querying.
Features of the Environmental Data Pipeline
Workflow Orchestration with Airflow: The pipeline uses Airflow to manage and schedule data collection tasks, as well as run data processing jobs. Airflow DAGs (Directed Acyclic Graphs) define the sequence and dependencies of operations, such as fetching weather data, processing it with Spark, and storing the results in PostgreSQL.
Scalable Data Processing with Spark: Apache Spark is a powerful distributed computing engine that can handle large-scale data processing tasks, enabling efficient analysis and transformation of environmental data.
Data Warehouse with PostgreSQL: The pipeline uses PostgreSQL as a centralized data warehouse to store processed data, making it easily accessible for querying and analysis. This structured storage solution is crucial for handling large volumes of data and supporting complex analytical queries.
Interactive Data Analysis with JupyterLab: JupyterLab provides a platform for developing data science notebooks, analyzing data, and creating visualizations in an interactive manner.
High-Performance Analytics with ClickHouse: For use cases that require rapid data querying and analysis, ClickHouse offers a highly optimized, columnar storage option.
How It Works: The Workflow Overview
Data Collection: The pipeline uses Airflow to periodically fetch weather data from OpenWeatherMap and air quality data from AirVisual APIs for multiple cities worldwide.
Data Processing: The collected data is processed with Apache Spark, which may involve data cleaning, transformation, or advanced analytics like machine learning.
Data Storage: The processed data is stored in PostgreSQL, acting as a data warehouse that supports complex queries and enables easy data retrieval for further analysis.
Interactive Data Analysis: JupyterLab enables interactive data exploration and analysis through Python notebooks, allowing data scientists to derive insights and create visualizations.
Optional High-Speed Analytics: For advanced analytics needs, data can be stored in ClickHouse, providing high-speed query capabilities for large datasets.
Step-by-Step Guide to Set Up the Pipeline
Step 1: Clone the Repository and Set Up Your Environment
Start by cloning the project repository:
git clone https://github.com/christophermoverton/environmental-data-pipeline.git
cd environmental-data-pipeline
Ensure that you have Docker and Docker Compose installed on your machine.
Step 2: Configure API Keys
Acquire API keys from OpenWeatherMap and AirVisual. Set these keys as environment variables in your Docker Compose file:
environment:
- OPENWEATHERMAP_API_KEY=your_openweathermap_api_key
- AIRVISUAL_API_KEY=your_airvisual_api_key
Step 3: Start the Docker Compose Services
Execute the following command to start all services:
docker-compose up -d
This command launches all required services, including Airflow, Spark, PostgreSQL (as the data warehouse), and JupyterLab, using Docker containers.
Step 4: Access and Manage Airflow DAGs
Navigate to the Airflow web UI at
http://localhost:8090
. Enable and trigger the DAGs for data collection (environmental_data_dag) and data processing (spark_processing_dag).
Environmental Data DAG: Collects weather and air quality data and stores it in PostgreSQL.
Spark Processing DAG: Runs a Spark job to process the collected data.
Step 5: Explore Data with JupyterLab
Access JupyterLab at
http://localhost:8888
. Use it to analyze the collected data interactively through notebooks located in the notebooks directory.
Applications and Use Cases
Real-Time Environmental Monitoring: Continuously monitor and analyze environmental data to detect trends and provide timely insights.
Research and Development: A robust platform for researchers working with large datasets to explore and analyze data effectively.
Public Health and Safety: Provides data-driven insights that can be used by policymakers and public health officials to address environmental issues.
Conclusion
The Environmental Data Pipeline offers a comprehensive, scalable, and flexible solution for managing environmental data. By integrating powerful tools like Apache Airflow, Apache Spark, JupyterLab, PostgreSQL (as a data warehouse), and Docker, this project provides a robust framework that is easy to deploy, extend, and use.
Whether you are a data scientist, researcher, or developer, this pipeline empowers you to collect, process, and analyze environmental data efficiently to gain valuable insights and make informed decisions.
Get Started Today!
Ready to dive into the Environmental Data Pipeline? Visit the GitHub repository to get started. Customize it, contribute to it, and help build a more data-driven world!